
You are currently browsing the category archive for the ‘Information Applications’ category.
Data virtualization is not new, but it has changed over the years. The term describes a process of combining data on the fly from multiple sources rather than copying that data into a common repository such as a data warehouse or a data lake, which I have written about. There are many reasons for an organization concerned with managing its data to consider data virtualization, most stemming from the fact that the data does not have to be copied to a new location. It could, for instance, eliminate the cost of building and maintaining a copy of one of the organization’s big data sources. Recognizing these benefits, many database and data integration companies offer data virtualization products. Denodo, one of the few independent, best-of-breed vendors in this market today, brings these capabilities to big data sources and data lakes.
Google Trends presents a graphic representation of the decline of the popularity of the term data federation and the rise in popularity  of the term data virtualization over time. The change in terminology corresponds with a change in technology. The industry has evolved from a data federation approach to today’s cost-based optimization approach. In a federated approach, queries are sent to the appropriate data sources without much intelligence about the overall query or the cost of the individual parts of the federated query. Each underlying data source performs its portion of the workload as best it can and returns the results. The various parts are combined and additional post-processing performed if necessary, for example to sort the combined result set.
of the term data virtualization over time. The change in terminology corresponds with a change in technology. The industry has evolved from a data federation approach to today’s cost-based optimization approach. In a federated approach, queries are sent to the appropriate data sources without much intelligence about the overall query or the cost of the individual parts of the federated query. Each underlying data source performs its portion of the workload as best it can and returns the results. The various parts are combined and additional post-processing performed if necessary, for example to sort the combined result set.
Denodo takes a different approach. Its tools consider the costs of each part of the individual query and evaluate trade-offs. As the saying goes, there’s more than one way to skin a cat; in this case there’s more than one way to execute a SQL statement. For example, suppose you wish to create a list of all sales of a certain set of products. Your company has 1,000 products (maintained in one system) and hundreds of millions of customer transactions (maintained in another system). The federated approach would bring both data sets to the federated system, join them and then find the desired subset of products. An alternative would be to ship the table of 1,000 products to the system that holds the customer transactions, load it as a temporary table and join it to the customer transaction data to identify the desired subset before sending the product data back to its source. Today’s data virtualization evaluates the costs in time of the two alternatives and selects the one that would produce the result set the fastest.
Data virtualization can make it easier, and therefore faster, to set up access to data sources in an organization. Using Denodo users connect to existing data sources, which become available as a virtual resource. In the case of data warehouses or data lakes, this virtual representation is often referred to as a logical data warehouse or a logical data lake. No matter how hard you work to consolidate data into a central repository, there are often pieces of data that have to be combined from multiple data sources. We find that such issues are common. In our big data integration benchmark research one-fourth (26%) of organizations said that data virtualization is a key activity for their big data analytics, yet only 14 percent said that they have adequate data virtualization capabilities.
therefore faster, to set up access to data sources in an organization. Using Denodo users connect to existing data sources, which become available as a virtual resource. In the case of data warehouses or data lakes, this virtual representation is often referred to as a logical data warehouse or a logical data lake. No matter how hard you work to consolidate data into a central repository, there are often pieces of data that have to be combined from multiple data sources. We find that such issues are common. In our big data integration benchmark research one-fourth (26%) of organizations said that data virtualization is a key activity for their big data analytics, yet only 14 percent said that they have adequate data virtualization capabilities.
Not all the work is eliminated by data virtualization. You must still design the logical model for the data that you want to provide, such as which tables and which columns to include, but that’s all. Virtualization eliminates load processes and the need to update the data. In the case of big data, there are no extra clusters to set up and maintain. The logical data warehouse or data lake uses the security and governance system already in place. As a result, users can avoid some of the organizational battles about data access since the “owner” of the data continues to maintain the rights and restrictions on the data. Our research shows that organizations that have adequate data virtualization capabilities are more often satisfied with the way their organization manages big data than are organizations as a whole (88% vs. 58%) and are more confident in the data quality of their big data integration efforts (81% vs. 54%).
In its most recent release, version 6.0, Denodo enhanced its cost-based query optimizer for data virtualization. Many of the optimizer’s features would be found in any decent relational database management system, but the challenge becomes greater when the underlying resources are scattered among multiple systems. To address this issue Denodo collects and maintains statistics about the various data sources that are evaluated at run time to determine the optimal way to execute queries. The product offers connectivity to a variety of data sources, both structured and unstructured, including Hadoop, NoSQL, documents and websites. It can be deployed on premises, in the cloud using Amazon Web Services or in a hybrid configuration.
Performance can be a key factor in user acceptance of data virtualization; users will balk if access is too slow. Denodo has published some benchmarks showing that performance of its product can be nearly identical to accessing data loaded into an analytical database. I never place much emphasis on vendor benchmarks as they may or may not reflect an actual organization’s configuration and requirements. However, the fact that Denodo produces this type of benchmark indicates its focus on minimizing the performance overhead associated with data virtualization.
When I first looked at Denodo, prior to the 6.0 release, I expected to see more optimization techniques built into the product. There’s always room for improvement, but with the current release the company has made great strides and addressed many of these issues. In order to maximize the software’s value to customers, I’d like to see the company invest in developing more technology partnerships with providers of data sources and analytic tools. Users would also find it valuable if Denodo could help manage and present consolidated lineage information. Not only do users need access to data, they need to understand how data is transformed both inside and outside Denodo.
with providers of data sources and analytic tools. Users would also find it valuable if Denodo could help manage and present consolidated lineage information. Not only do users need access to data, they need to understand how data is transformed both inside and outside Denodo.
If your organization is considering data virtualization technology, I recommend you evaluate Denodo. The company won the 2015 Ventana Research Technology Innovation Award for Information Management, and its customer Autodesk won the 2015 Leadership Award in the Big Data Category. If your organization is deluged with big data but is not considering data virtualization, it probably should be. As our research shows, it can lead to greater satisfaction with and more confidence in the quality of your data.
Regards,
David Menninger
SVP & Research Director
Follow Me on Twitter @dmenningerVR and Connect with me on LinkedIn.
On Monday, March 21, Informatica, a vendor of information management software, announced Big Data Management version 10.1. My colleague Mark Smith covered the introduction of v. 10.0 late last year, along with Informatica’s expansion from data integration to broader data management. Informatica’s Big Data Management 10.1 release offers new capabilities, including for the hot topic of self-service data preparation for Hadoop, which Informatica is calling Intelligent Data Lake. The term “data lake” describes large collections of detailed data from across an organization, often stored in Hadoop. With this release Informatica seeks to add more enterprise capabilities to data lake implementations.
This is the latest step in Informatica’s big data efforts. The company has been investing in Hadoop for five years, and I covered some of its early efforts. The Hadoop market has been evolving over that time, growing in popularity and maturing in terms of information management and data governance requirements. Our big data benchmark research has shown increases of more than 50 percent in the use of Hadoop, with our big data analytics research showing 37 percent of participants in production. Building on decades of experience in providing technology to integrate and manage data in data marts and data warehouses, Informatica has been extending these capabilities to the big data market and Hadoop specifically.
The Intelligent Data Lake capabilities are the most significant features of version 10.1. They include self-service data preparation, automation of some data integration tasks, and collaboration features to share information among those working with the data. The concept of self-service data preparation has become popular of late. Our big data analytics research shows that preparing data for analysis and reviewing it for quality and consistency are the two most time-consuming tasks, so making data preparation easier and faster would benefit most organizations. Recognizing this market opportunity, several vendors are competing in this space; Informatica’s offering is called REV. With version 10.1 the Big Data Management product will have similar capabilities, including a familiar spreadsheet-style interface for working with and blending data as it is loaded into the target system. However, the REV capabilities available as part of Informatica’s cloud offering are separate from those in Big Data Management 10.1. They require separate licenses and there is no upgrade path or option as a result sharing work between the two environments is limited. Informatica faces two challenges with self-service: how well users view its self-service capabilities and user interface vs. those of their competitors and whether analysts and data scientists will be inclined to use Informatica’s products since they are mostly targeted at the data preparation process rather than the analytic process.
The collaborative capabilities of 10.1 should help organizations with their information management processes. Our most recent findings on collaboration come from our data and analytics in the cloud research, which shows that only 30 percent of participants are satisfied with their collaborative capabilities. The new release enables those who are working with the data to tag it with comments about what they found valuable or not, note issues with data quality and point others toward useful transformations they have performed. This type of information sharing can help reduce some of the time spent on data preparation. Ideally these collaboration capabilities could be surfaced all the way through the business intelligence and analytic process, but Informatica would have to do that through its technology partners since it does not offer products in those markets.
Version 10.1 includes other enhancements. The company has made additional investments in its use of Apache Spark both for performance purposes and for its machine-learning capabilities. I recently wrote about Spark and its rise in adoption. More transformations are implemented in Spark than in Hadoop’s MapReduce, which Informatica claims speeds up the processing by up to 500 percent. It also uses Spark to speed up the matching and linking processes in its master data management functions.
I should note that although Informatica is adopting these open source technologies, its product is not open source. Much of big data development is driven by the open source community, and that presents an obstacle to Informatica. Our next-generation predictive analytics research shows that Apache Hadoop is the most popular distribution, with 41 percent of organizations using or planning to use this distribution. Informatica itself does not provide a distribution of Hadoop but partners with vendors that do. Whether 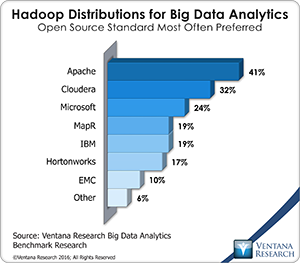 Informatica can win over a significant portion of the open source community remains a question. Whether it has to is another. In positioning release 10.1 the company describes the big data use cases as arising alongside conventional data warehouse and business intelligence use cases.
Informatica can win over a significant portion of the open source community remains a question. Whether it has to is another. In positioning release 10.1 the company describes the big data use cases as arising alongside conventional data warehouse and business intelligence use cases.
This release includes a “live data map” that monitors data landing in Hadoop (or other targets). The live data map infers the data format (such as social security numbers, dates and schemas) and creates a searchable index on the type of data it has catalogued; this enables organizations to easily identify, for instance, all the places where personally identifiable information (PII) is stored. They can use this information to ensure that the appropriate governance policies are applied to this data. Informatica has also enhanced its security capabilities in Big Data. Its Secure@Source product, which won an Innovation Award from Ventana Research last year , provides enterprise visibility and advanced analytics on sensitive data threats. The latest version adds support for Apache Hive tables and Salesforce data. Thus for applications that require these capabilities a more secure environment is available.
The product announcement was timed to coincide with the Strata Hadoop conference, a well-attended industry event that many vendors use to gain maximum visibility for such announcements. However, availability of the product release is planned for the second quarter of 2016. As an organization matures in its use of Hadoop, it will need to apply proper data management and governance practices. With version 10.1 Informatica is one of the vendors to consider in meeting those needs.
Regards,
David Menninger
SVP & Research Director
 LinkedIn
LinkedIn Twitter
Twitter Facebook Fan Page
Facebook Fan Page Ventana Research Website
Ventana Research Website